问答百科
问答百科特征选择(区别于特征提取)
特征选择和特征提取的异同
先来看一张特征工程的图。
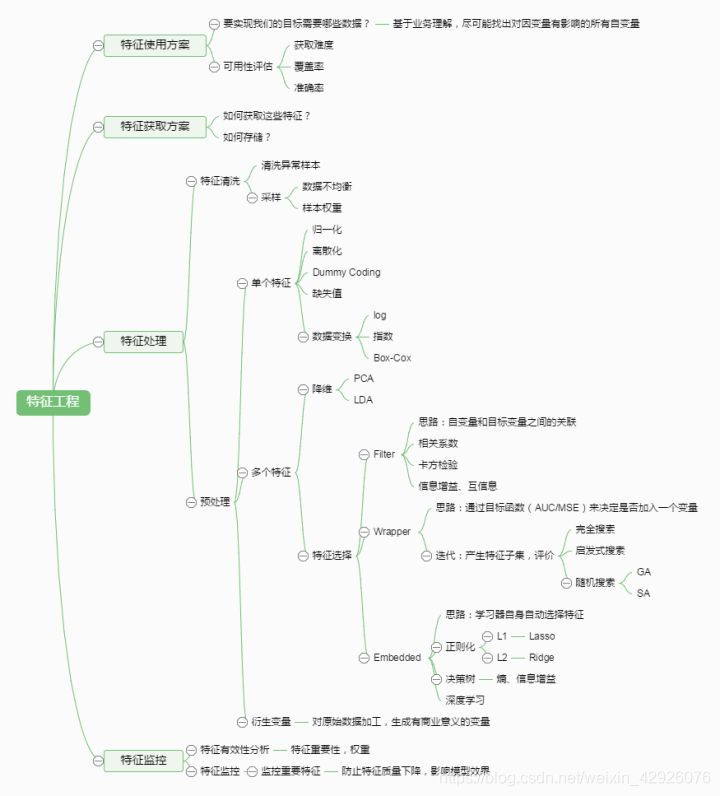
特征选择和特征提取都是特征工程下,对于多特征的预处理。
其共同的目的是:
特征提取和特征选择统称为降维。( )(针对于the curse of (维度灾难),都可以达到降维的目的。)
看一下,以下的图片:
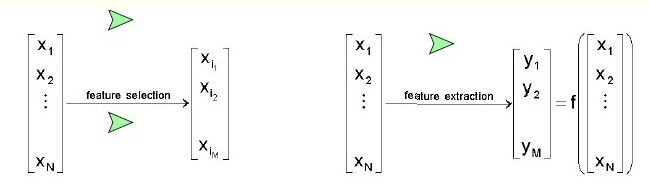
用数学的话来解释:
特征选择后的特征是原来特征的一个子集。
特征提取后的新特征是原来特征的一个映射。
用通俗的话来解释他们的不同:
打比方来说:
有长、宽两个特征,特征选择是根据模型的目标来选择长这个特征或者选择宽这个特征,而特征提取是把长和宽两个特征提取成面积这个“新特征”。
接下来回归主题,讲讲特征选择。
参考文献:[Peng, H.Long, F.Ding, C. for .1997]
特征选择
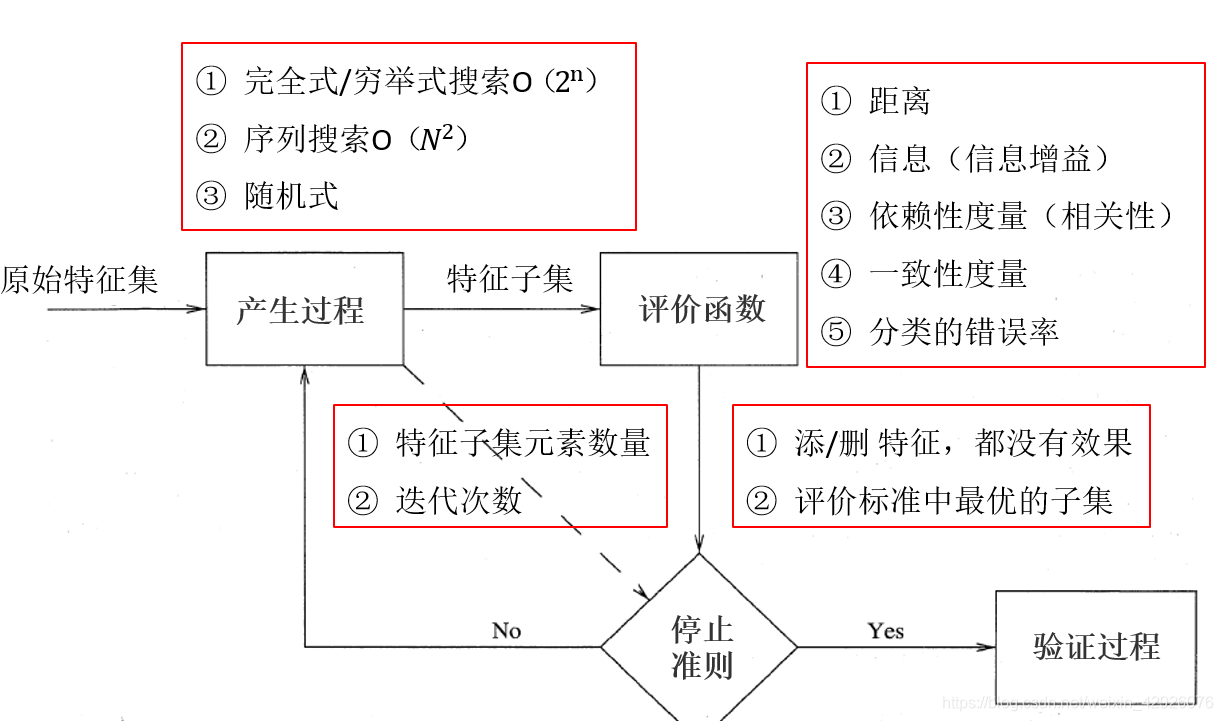
产生过程(搜索过程)
(或可理解为搜索特征子集的过程)。
完全式/穷举式:根据评价函数从2^n个候选子集中选出最优的 。能够找到最优解,但其缺点是它会带来巨大的计算开销,尤其当特征数比较大的时候,计算时间很长。
序列式:它避免了简单的穷举式的搜索,在搜索过程中依据某种次序(比如向前、向后)向当前特征子集中添加或删除特征,从而获得优化过的特征子集。典型的算法有:向前向后搜索、浮动搜索、双向搜索等。算法的优点是比较容易实现,计算的负责度相对较小(时间复杂度为O(2^n)),但容易局部最优。
随机式:从某个候选特征子集开始,依照一定的启发式信息和规则逼近全局最优解(注意不是最优解,而是逼近最优)。例如:遗传算法、模拟退火算法、粒子群算法和免疫算法等。
评价函数 距离度量(欧氏距离等)信息度量(信息增熵)依赖性度量(相关性)——特征K与C类的相关性大于特征Y与C的相关性,则特征K优先于特征Y。举例子来说,喉结这个特征与男性类的相关性大于身高这个特征,则喉结特征优先于特征Y。一致性度量(没搞明白,待续)分类错误率

生成过程(搜索过程)+不同的评价函数=特征选择方法
停止准则
产生过程(搜索过程)对于停止准则:
评价函数对于停止准则:
问题和思考
坐标横竖轴表示不同的特征,条形图的高度为统计不同样本的数量,散点图的点和小圆圈表示样本,以下问题皆如此
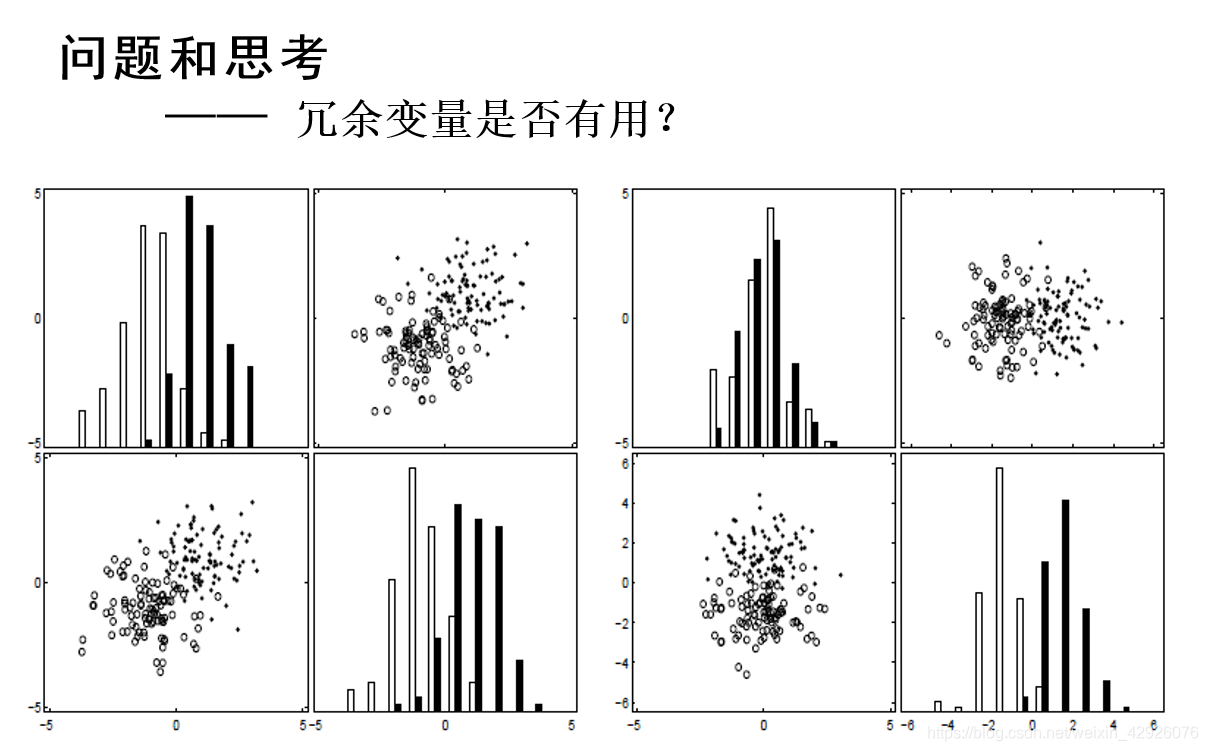
结论一:通过添加可能冗余的变量,可以降低噪声,从而实现更好的类分离。
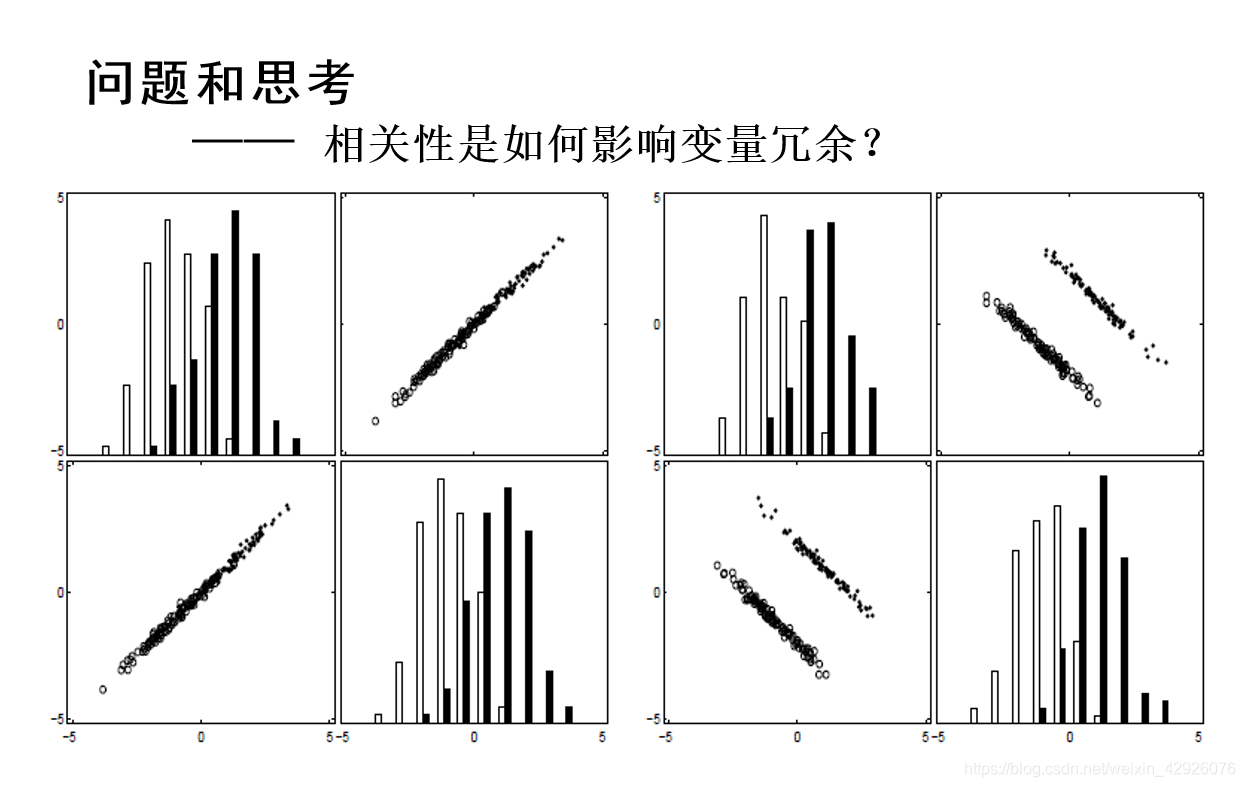
结论二:
完全相关的变量确实是冗余的;非常高的变量相关性(或反相关性)并不意味着没有变量互补性。2. 非常高的变量相关性(或反相关性)并不意味着没有变量互补性。
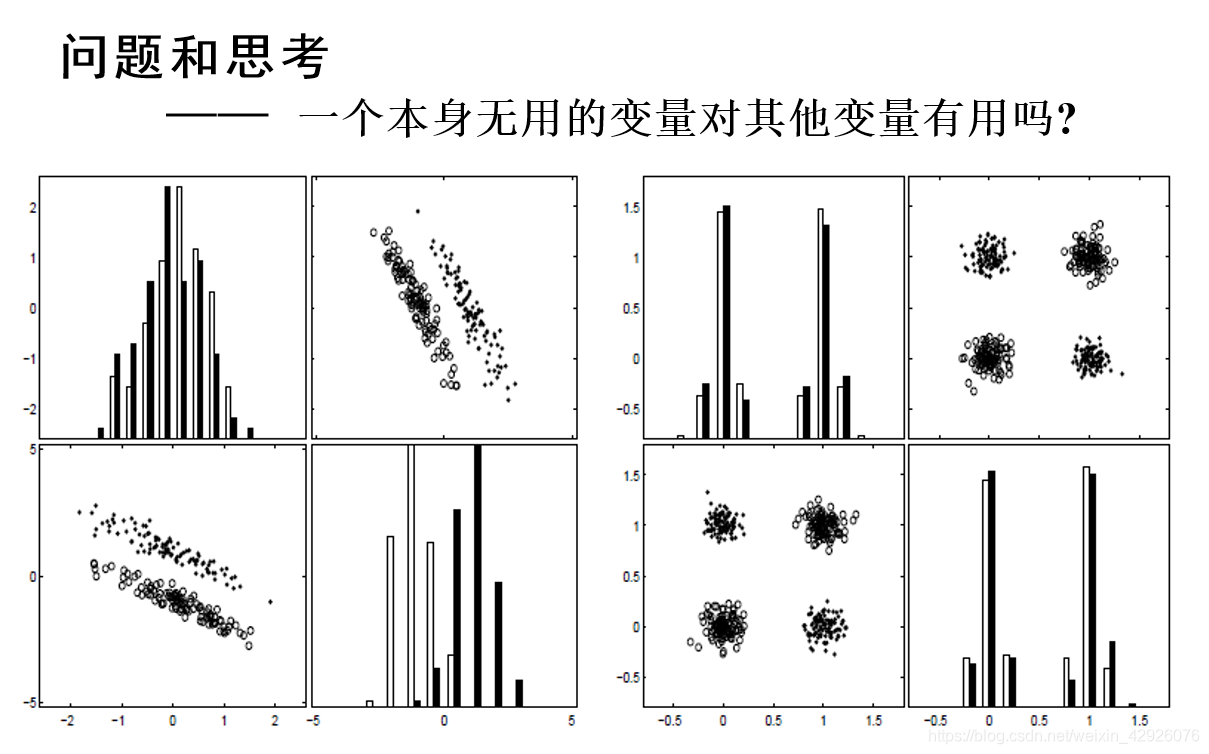
结论三:
当与其他变量一起使用时,完全无用的变量本身可以提供显著的性能改进;无用的变量+无用的变量=有用的变量。